Summary
Symptom
Attempts to change the OUTDIR keyword by running newdir command result in this error:
ERROR - MDS Error (13): Not connected to ICE server. Try connect.
Error setting outdir: ERROR - ERROR - MDS Error (13): Not connected to ICE server. Try connect
Problem
The MOSFIRE detector server is not connected to the ICE server.
Solutions
Follow these steps to re-connect to the ICE server. The trouble shooting efforts outlined here start small and build up to larger efforts.
Solution 1 (can be done by observer)
Isn't it a lovely night for a stroll ...
- On the MOSFIRE desktop, display the Exposure Engineering GUI.
- Click the Connect button to re-establish the connection to the ICE server. Verify that the button labeled Connected: changes from OFF to ON.
- If the button labeled Ready: is not currently set to ON, then click the Resume button.
- From an xterm window on mosfireserver, execute the newdir command and verify that it now runs without error.
Solution 2
Start dusting off the cobwebs gunslinger, because this is starting to get ugly.
If you try option 1 a handful of times and it does not work, try this next:
- Power cycle the augmentix using the power control GUI on the engineering menu.
- Wait 3 min.
- Try the connect and init functions a couple of times.
- Don't forget to restart the
touchyz.bat and
rotateLog.bat processes on the Augmentix machine.
Solution 3
Steady there Gunslinger. Panicking will only get you into more trouble.
If you try option 2 and it does not work, try this next:
- Power cycle the Jade2 using the power control GUI on the engineering menu.
- wait 30 sec.
- try the connect and init functions a couple of times.
- Failing that try a powercycle of the augmentix one more time.
Solution 4
The zombies are walking your way Gunslinger, but I have high hopes for you
This will take about 15 min to shut everything down and to reboot the host machines. Of course you need to get SWOC involved because they need to complete the reboots. First resolved using the computer reboot method on 3 Aug 2015 (Marc, Dwight, and Julia).
- Shutdown the MOSFIRE operational software.
- Reboot kaimana (mosfire unix detector server) - SWOC does this.
- Reboot nuu (mosfire host) - SWOC does this.
- Run
ctx on nuu when it reboots and take appropriate action if needed (may need to restart all mosfire servers:
mosfire restart servers).
Solution 5
You are running out of bullets gunslinger, and the zombies are closing in. LOOK OUT!
Time to try a different data taking disk. Maybe the disk is at fault. Follow the instructions at Augmentix disk swap procedure (software and hardware swaps) to swap which disk we use via software.
If you think that you need to swap the physical disk hardware, consider this ... if you are not MOSFIRE's Yoda, you should get a MOSFIRE jedi on the line right now. And summit assistance may be required. First resolved using a disk swap software method on 4 Sept 2015 (Marc & Julia). Hardware swaps completed twice in the past (pre Sept 2015).
Symptom
GUIs stop updating. The MOSFIRE server and other servers status indicators located at the bottom of the the MDesktop may turn red. In addition, a server error is displayed in MDesktop and MSCGUI. An examination of the mosfire server logs reveals messages such as:
mosfire_trigger: Trigger loop already in progress. Exiting.
and
!ERROR! could not write msg for KEYWORD to send Q (Resource temporarily unavailable)
For a crash, the global server will be down.
Problem
A global server client is blocked or hanging, and the global server is attempting to broadcast a keyword update to it, but it becomes blocked in this attempt. This could indicate a stale client connection (connection persists; i.e., is still registered as a client in the global server even though client is dead). Starting and stopping clients rapidly appears to aggravate this situation.
Solution
A restart of the global server may be needed. Follow these steps:
- Determine whether the server is merely hung or actually crashed by typing
gpsserv mosfire_
If the output lists 2 processes, the global server has not crashed but it may be hung; see recovery from blocked server. If the output lists only 1 server then this is a true crash and you should continue with this procedure.
- Terminate all non-desktop global server clients. Verify that all clients using waitfor have been terminated by executing
gps waitfor
and check that nothing is listed (except fgrep).
- Restart the global server by doing either of the following:
- Check that the global server is broadcasting to clients by executing
cshow -s mosfire mmf1scycle mdscycle
and confirm that the keywords increment. If so, then restart the waitfor clients and proceed with observing. If not, then kill all GUIs (desktop, MAGMA, OA eavesdrop, etc.) repeat this procedure.
- Verify that the server indicators at the bottom of the MOSFIRE desktop turn green. The MOSFIRE desktop will automatically reconnect to the new server. If you suspect something is wrong on the desktop, restart the desktop by selecting
MOSFIRE Control Menu > Subcomponents... > Re-Start Desktop
Symptom
Similar to global server hang. GUIs unresponsive. The MOSFIRE server and other servers status indicators located at the bottom of the the MDesktop may turn red, In addition, a server error is displayed in MDesktop and MSCGUI.
Problem
The global server is hung.
Solution
A restart of the global server is likely necessary. Follow these steps:
- Determine whether the server is merely hung or actually crashed by typing:
gpsserv mosfire_
If the output lists only 1 server then this is a true crash and you should continue with the procedure above for recovery from global server crash. If the output lists 2 processes, the global server has not crashed but it may be hung; continue with this procedure.
- Check that the global server is broadcasting to clients by executing
cshow -s mosfire mmf1scycle mdscycle
and confirm that the keywords increment. If so, then kill and restart all MOSFIRE GUIs (desktop, MAGMA, OA eavesdrop, etc.), thereby unblocking the server, and proceed with observing. If not, then then continue to next step.
- Terminate all non-desktop global server clients, including CSU alerts and Xobslog. Verify that all clients using waitfor have been terminated by executing
gps waitfor
and check that nothing is listed (except fgrep).
- Restart the global server by doing either of the following:
- Check that the global server is broadcasting to clients by executing
cshow -s mosfire mmf1scycle mdscycle
and confirm that the keywords increment. If so, then restart the waitfor clients and proceed with observing. If not, then kill all GUIs (desktop, MAGMA, OA eavesdrop, etc.) repeat this procedure.
- Verify that the server indicators at the bottom of the MOSFIRE desktop turn green. The MOSFIRE desktop will automatically reconnect to the new server. If you suspect something is wrong on the desktop, restart the desktop by selecting
MOSFIRE Control Menu > Subcomponents... > Re-Start Desktop
- Symptom
- Image fails to appear on disk or on image display. The MDS
indicator on the MOSFIRE desktop is red. The testAll script indicates that the MDS is
in a bad state.
- Problem
- The MDS (MOSFIRE datataking service) has crashed.
- Solution
-
- Restart MDS server from the background menu by
selecting:
MOSFIRE Control Menu > Subcomponents > Restart Servers > Restart detector
or by executing these commands on mosfireserver:
mosfire stop mds
mosfire start mds
- Run testAll to verify that
the status of MDS is now OK.
- On the Exposure Control GUI on the MOSFIRE desktop,
click on CONNECT and verify that the corresponding indicator
light turns green.
- On the Exposure Control GUI on the MOSFIRE desktop,
click on RESUME and verify that the corresponding indicator
light turns green.
- Run testAll to verify that
the status of Checking datataking system is OK.
- Kill the observer ds9 tool by clicking File >
Exit.
- From the mosfireserver command line, execute
the command
mosfire stop autodisplay
to terminate the Python process
mosfireMonitorAndDisplay.pyc.
- Restart autodisplay and ds9
from background menu via
MOSFIRE Control Menu > Subcomponents... > Re-start Image Display
- Execute the newdir command on the
mosfireserver command line to reset the data
directory.
- Acquire a test image and verify that it appears on the
image display and is written to disk.
- Symptom
- Guis become partly responsive, but it does not appear to be
working correctly. A view of the log file using the pulldown
menu option: MOSFIRE Engineering Menu -> Logfile Menu -> Log
Tail -> Tail Mosfire (global server) logfile. Warning
message indicates that the Message queue is increasing. Or
that the message queue is full:
!WARNING! Stalled client: Mon Mar 6 16:37:48 2017
The msg Q now contains 8192 msgs
- Problem
- The global server communication is blocked. No further
action may occure until the global server is restarted.
- Solution
-
- Stop the software: MOSFIRE Control Menu ->
Close MOSFIRE windows (GUIs)
- Run checkrpc in mosfire server window
- If tasks remain Kill remaining rpc tasks with either:
- checkrpc -k
- mosfireKillAllClients
- Restart the global server: MOSFIRE Engineering Menu ->
MOSFIRE Trouble Recovery Menu -> Restart Global Server
- Restart the guis. Reset observer name and directory.
- If this does not work, or message re-occurs, open a mosfireserver terminal and run mosfireRestartGlobalServer [note that this must be done in the mosfire account, pw in
showpasswords.]
- Then restart the guis as in step 5.
- Symptom
- kEventSounds/soundplay utility does not echo event sounds.
- Problem
- The soundplay utility may not be running on your machine.
- Solution
- Option 1:
In an xterm on the thin client, type
/home/user/bin/soundplay -s svncserver1:9798 -T mosfire -px /usr/bin/aplay
- Option 2:
See the common VNC troubleshooting entry for a solution.
trouble.html#vnc9 . You may have to click the
Technical Index link to gain access. Login info required.
- Symptom
- Calibration tool seems to have stalled without any error message,
as though it is waiting for something.
- Problem
- A process associated with the calibration script may be waiting for a
mechanism to complete its move even if that move was completed.
- Solution
-
Kill the process by selecting the following from the background menu:
MOSFIRE Engineering Menu -> MOSFIRE Trouble Recovery Menu -> Kill WAITFOR Tasks
The calibration script should resume shortly.
Alternatively, if you can determine which mechanism it is waiting on, you can command that mechanism to move to that destination (if it is already there, you will have to move away first). For example, if the script is waiting on hatch closed and the hatch is already closed, command hatch open, wait for it to get there, then command it closed again. This will sometimes trigger the response which the script it waiting on.
- Symptom
- Calibration tool script failed with the following error
root : ERROR Remaining args are not a multiple of 5
- Problem
- A mask file name may contain spaces, and the calibration script incorrectly interpreted the file name.
- Solution
- Ask the observers to rename the mask without spaces, and reupload it.
When troubleshooting MOSFIRE services, sometimes the services do not come up properly. Here's some advice which may be useful, but which is based on anecdote, not on proper data.
- Before stoping or starting a service, always stop the global server with
mosfire stop mosfire, then start the global server up last with mosfire start mosfire
- If you are starting a service which appears to be having a problem always stop the service (
mosfire stop [servicename]) before starting it up again, even if it already appears to be down based on the output of ct or ctx.
- It may also be worth waiting a few seconds after stopping a service before starting it back up.
- Always check the output of the service's log to see whether it started up ok.
Thus, the typical process for restarting a troublesome service should be:
mosfire stop mosfiremosfire stop [servicename]- Wait a few seconds
mosfire start [servicename]tail /sdata1300/logs/server/[servicename]/[servicename].log and examine the output.mosfire start mosfire- Because the global server has been restarted, some of the GUIs may be unhappy at this point, so give them a few seconds to recover or restart them as needed.
Sometimes when running mosfireConnect the instrument does
not start up properly. One can often get in to a very confusing situation,
so here are a few pieces of advice on how to work tour way out of this
situation:
- Always start from a fully "disconnected" state by running
mosfireDisconnect and also confirming that all
services are shut down by checking the output of ctx. If
any services are still running at that point, kill them explicitly.
- Always make sure that the mosfire services are running as user
mosfire and not some other user.
- If needed, bring up services individually using
mosfire start [servicename] and confirming that they are
running properly after each one. At this point, run
mosfireConnect and look for errors.
- Check for basic network connectivity by pinging the CSU computer
(control1), though check to see if it is powered on (using
showpower or looking at keywords under the
mp1s and mp2s services). If control1 is not
on, it won't respond to ping! Also be aware that control1 can take a
very long time to boot up (~5 minutes).
- If you are still having trouble ask day crew to inspect and clean
the fibers which provide connectivity to the instrument. Do this for
both fiber ends (at the instrument and in the server room).
- As a last resort, try looking at the source code for
mosfireConnect and running it line by line, but beware that
this is more difficult than it sounds because there are numerous case
statements and some case statement shave the same subject listed twice
and you need to run both cases for this to work.
If sounds are not working and eventsounds is showing an error about not
being able to connect, check that soundboard is running on
vm-mosfire using:
ps -elf | grep soundboard | grep -v grep
If no soundboard process is running, start one using:
$RELDIR/etc/init.d/mosfiresoundboard
- Symptom
- Image concludes prematurely, and exposure status in
Exposure Status GUI indicates a Exposure Aborted (Read
Timeout): Writing FITS file. If
in middle of dither pattern, the dither pattern sequence
will proceed and will skip the current position. If this
happens, the status message will be overwritten in the
status gui. ABORTED FITS
header keyword in image is T, even though abort not
initiated by user.
- Problem
- The Jade2 electronics failed to read all data from Sidecar.
A timeout occurred waiting for new data to arrive.
- Solution
- Just continue operations as normal. We have not seen this
issue persist, and subsequent exposures (triggered manually
or in the next image in the dither pattern) proceed as normal.
- Symptom
- MOSFIRE Dataset Status panel displays message ERROR:
lost communication to sidecar server. Warning message
ICE Timeout Exception in the Expsure gui and message
queue. Images fail to write to disk.
- Problem
- The Sidecar server has died.
- Solution
-
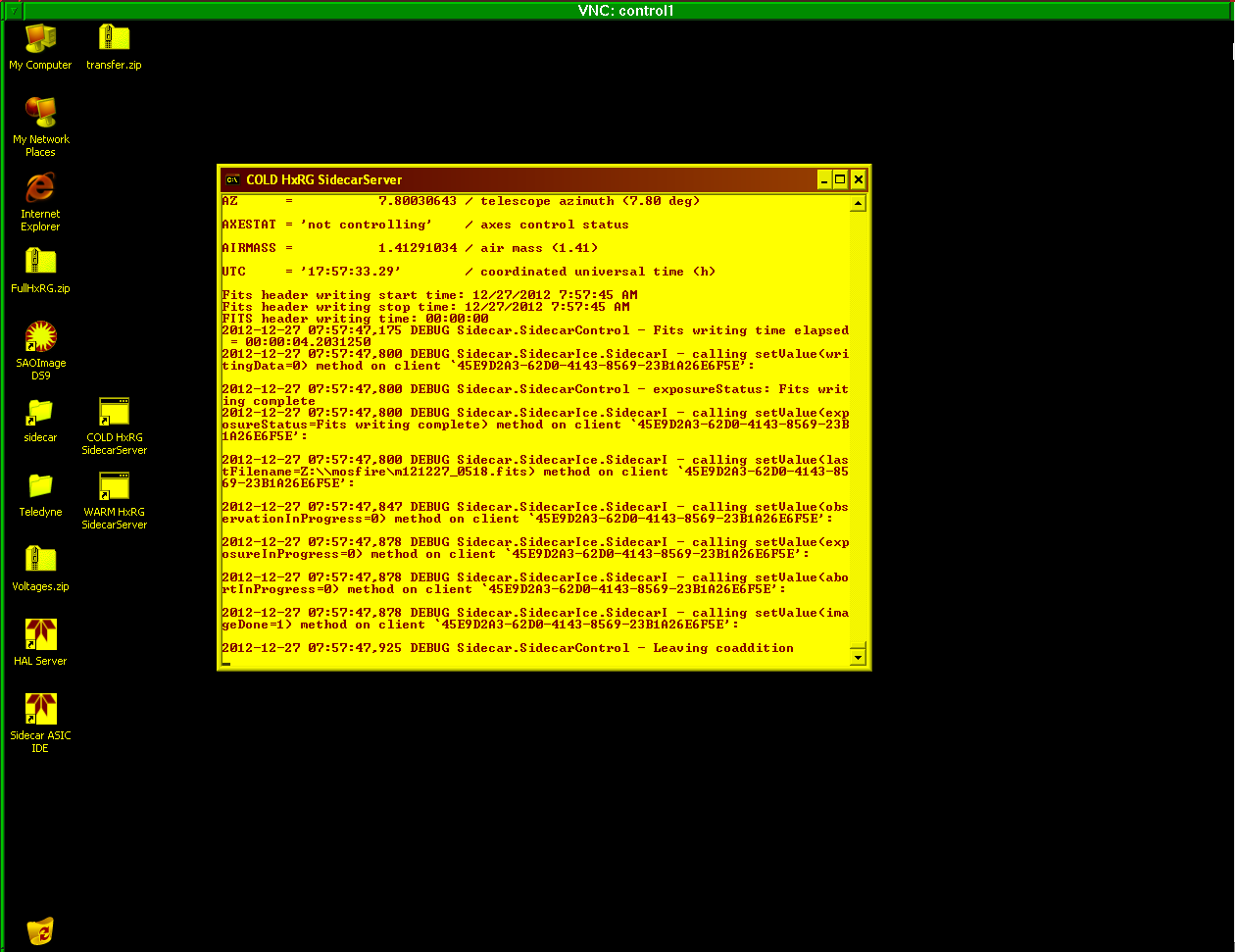
- Restart the Sidecar server as follows:
- Open an xterm on
mosfireserver under any MOSFIRE account.
- Execute the command
vncviewer control1
to connect with the VNC session on the augmentix
computer. The password can be found in the SA
password list.
- Kill the existing Sidecar server session by
clicking the X at the top right of the
COLD HxRG SidecarServer terminal window. See screenshot.
- Re-start the Sidecar server session by
double-clicking the desktop shortcut labeled
COLD HxRG SidecarServer. Verify that this
launches a new terminal window and that messages start
scrolling down the window.
- Restart the MDS:
- Open an xterm on
mosfireserver under any MOSFIRE account.
- Execute the command
mosfire stop mds
.
- Wait 5 seconds.
- Execute the command
mosfire start mds
- Execute the command
modify -s mds resume=1
- Reset Data Dir: run newdir in a mosfireserver xterm
- Take a test image and check the image size on disk. If
the size is smaller than 16853760 bytes, then follow the
procedure to recover missing image headers.
- Symptom
- MOSFIRE Dataset Status panel displays message ERROR:
lost communication to sidecar server. Warning message
ICE Timeout Exception in the Expsure gui and message
queue. Images fail to write to disk.
and/or
Subsequent attempts to connect MDS to the sidecar fail
almost immediately (mds connected=0 and you may be able to
take images, strangely)
- Problem
- The time on control1 may not match mosfireserver
- Solution
-
- Re-sync the time on control1:
- Open an xterm on
mosfireserver under any MOSFIRE account.
- Execute the command
vncviewer control1
to connect with the VNC session on the augmentix
computer. The password can be found in the SA
password list.
- Click on the time in the lower right corner to
bring up the Windows time dialog
- Click on the "Internet Time" tab
- Click "Update Now" and wait about 10 seconds
- Look for a "Success" message. If the sync fails,
repeat the click "Update Now" step until it succeeds
- Restart the Sidecar Server on control1
- Kill the existing Sidecar server session by
clicking the X at the top right of the
COLD HxRG SidecarServer terminal window. See screenshot.
- Re-start the Sidecar server session by
double-clicking the desktop shortcut labeled
COLD HxRG SidecarServer. Verify that this
launches a new terminal window and that messages start
scrolling down the window.
- Restart the MDS:
- Open an xterm on
mosfireserver under any MOSFIRE account.
- Execute the command
mosfire stop mds
.
- Wait 5 seconds.
- Execute the command
mosfire start mds
- Execute the command
modify -s mds resume=1
- Reset Data Dir: run newdir in a mosfireserver xterm
- Take a test image and check the image size on disk. If
the size is smaller than 16853760 bytes, then follow the
procedure to recover missing image headers.
- Symptom
- Attempt to acquire an exposure in one
of the "Dark" configurations fails; datataking system indicates
filter mismatch.
- Problem
- The requested and actual filter positions differ.
- Solution
- Reset the demanded filter position to plain Dark
by executing the recovery script from the background menu:
MOSFIRE Engineering > Trouble Recovery Menu > Reset Dark Filter
or by issuing the command-line directive:
modify -s mosfire filtertarg=Dark
- Symptom
- Unable to take images, attempts to resume MDS fail, one
sees errors in SidecarServer output on control1.
- Problem
- The Jade2 electronics are in a bad state
- Solution
- Power cycle all hardware. Do not do this lightly as there is the
possibility of inducing detector artifacts (not yet seen on
MOSFIRE). This is most easily accomplished by:
- mosfireDisconnectWithDate
- wait a few seconds
- mosfireConnectWithDate
- Symptom
- When attempting to take images by clicking Wait & Go
button on MOSFIRE desktop, the data acquisition process exits
within seconds with the following error:
A mechanism error has occured. mosfireWfMechs exiting.
- Problem
- One or more mechanisms are not at their targeted
positions.
- Solution
-
- Execute mosfireWfMechs on the command line
to receive helpful diagnostic information such as:
Error with PUPIL move: status=MISMATCH
which will indicate which stage is out of position.
- Consult the Mechanism Status GUI on the MOSFIRE Desktop
to confirm that all stages are at their targeted
positions.
- If needed, re-send motor moves to send stages to
desired positions. Note that the pupil rotator may
report that the target position is open but
that the actual position is some number such as
-43751. This is acceptable.
- If you have determined that the conditions are
acceptable for continuing with the exposure, click the
selector beside Wait & Go and select
Go. This will circumvent the step of running
mosfireWfMechs before the exposure and allow
you to acquire data despite the error condition.
- Symptom
- The Wait & Go button on the MOSFIRE desktop
Exposure Control widget is inactive (greyed out), preventing you
from starting an exposure; however, exposures can still be acquired
using the goi command.
- Problem
- The SCRIPTRUN keyword is set to a non-zero
value, perhaps as the result of aborting a script.
- Solution
-
Reset the SCRIPTRUN keyword using either of the
following methods:
- Execute the following on the command line:
modify -s mosfire SCRIPTRUN=0
- OR, from the FVWM background menu, select:
MOSFIRE Engineering Menu > MOSFIRE Trouble Recovery Menu > Reset SCRIPTRUN keyword
This should immediately restore the Wait & Go
button to “active” mode.
- Symptom
- Data taking sequence is aborted becasue it is waiting for
an exposure to complete.
- Problem
- The detector logging script in the Sidecar Server has not
been started.
- Solution
-
Start the detector logging script following
this procedure
(requires password).
- Symptom
- Data taking fails
- Problem
- The C drive on the augmentix may be full. This is ideally
prevented via IPM task #611.
- Solution
-
Below are the same instructions for cleaning up the log files
as the instructions appear on the IPM #611 task.
- login to mosfireserver as mosfire
- Start a "vncviewer control1"
- navigate to C:sidecarSidecarServerLogs
- select all sidecar_*.log files
- delete the log files (ensure Recycle bin is empty)
- close sidecar directory
- close the vnc session
You may need to reconnect to the sidecar server to re-initiate data
acquisition.
- Symptom
- SAT complains about images not having enough headers or not enough extensions.
- Image files in disk are smaller than the usual 16853760
bytes.
- show -s mosfire csuextname results in none.
- Problem
- The header information is not written in the FITS headers
following a restart of the detector server.
- Solution
- In MAGMA:
- Setup an mask different to the current one.
- Setup the current mask.
- Execute the current mask.
Take an image and check that the size on disk is 16853760 bytes.
- Symptom
- After hitting Wait & Go nothing happens. The
exposure progress bar is no updated and the Wait & Go button
remains innactive. No error message appears on the Exposure Status
window.
- Problem
- The detector server does not respond.
- Solution
- Power cycle the detector control system. On the background
menu select Mosfire Engineering Menu --> Engineering Gui
Menu --> Power control GUI Under Cabinet A.
- Power OFF the Computer
- Power OFF Jade2.
- Power ON Jade2
- Wait for 30 seconds.
- Power ON Computer.
- Wait for minutes.
- Select the camera icon on the top left side of the
MOSIFRE desktop menu. In the popup window (Exposure System) select:
- Symptom
- You are unable to connect or init the exposure system (e.g. using the connect and init buttons in the window which comes up when you click the camera icon on the top left side of the MOSIFRE desktop menu)
- Problem
- The data taking computer (aka augmentix) system time does not agree with mosfireserver.
- Solution
- Reset the time in Windows to match the mosfireserver time. This is usually accomplished by syncing it via NTP (aka "internet time"). Use the windows time and date tool or ask IT support for help.
- Symptom
- Grating mechanism fails to reach intended target. Position
of grating mechanism in status GUI shows "Unknown". Switch
value (show -s mmgts switch) does not match target switch
value (most easily obtained using mosfireShowMechPositions
mmtgs).
- Problem
- The mechanism is moving past intended target position and
hitting the limit switch in the negative (grating)
direction. Under normal execution, the mechanism is supposed
to stop when it hits the stop switch, and when this happens,
only it and the position switch should be activated.
- Solution
- Re-execute the move by using Observing Mode GUI or global
server keyword modify -s mosfire
setobsmode=filter-grating.
Optional: we may be able to recover from this by backing
the mech away from the limit switch (modify -s mmgts
step=10).
If the above fails try lower level moves:
- First move
to safe location by executing modify -s mmgts targname="safe
grating"
- Move back to grating position by executing modify
-s mmgts targname=HK or mosfire -s mmgts
targname=YJ.
Symptom
The data is bad. Typically this would appear either as the data bring all zeros or a "picture frame" (the detector structure is visible).
Problem
This is a known error which affects roughly 1 in 800 MOSFIRE images. One of the detector reads is missed.
Solution
No known solution.
- Symptom
- After switching filters that requires the pupil to
transition from open to tracking or tracking to open, the
mechanism appears hung. The move never finishes and the status
indicates that it is still moving, but possibly
the target position says that it is tracking or open.
- Problem
- Unknown at this time. Likely multiple issues each addressed by one
or more of the options below.
- Solution
-
There are four possible solutions:
Option A:
- Click the Home button on the mdesktop.
- Click on Home Pupil Rotator
- On the Observing Mode GUI, select H imaging and wait for
the pupil to be fully open. The Mechanism Status GUI should
show Open in the Pupil Status and Target fields.
- >On the Observing Mode GUI, select Ks imaging and wait for
the pupil to be tracking. The Mechanism Status GUI should
show Tracking in the Pupil Target field and a number
in the Status field.
Obtion B:
- In a mosfire server window, execute these commands in a
mosfireserver window:
modify -s mmprs reset=1
modify -s mmprs home=1
and reselect the filter mode.
- If the above does not work, , execute these commands in a
mosfireserver window:
modify -s mmprs zero=1
modify -s mmprs reset=1
modify -s mmprs home=1
and reselect the filter mode. Zero will set the current
location counter to zero. Reset=1 resets the controller, and
the home initializes the stage.
Option C:
When the above two options fail to recover, try
restarting both the sub server and the global
server. This helped on 7 March 2017.
- mosfire stop mmprs
- mosfire stop mosfire
- mosfire start mmprs
- mosfire start mosfire
Option D:
- Check the value of the
rotservo keyword using:
show -s mmprs rotservo
- If
rotservo is 0, run the
mosfireSetupPupilTracking script.
- Confirm that
rotservo is now 1.
- Attempt to set your mode (imaging or spectroscopy) again and confirm
that the pupil is tracking properly on the GUI.
Note that the zero and reset actions should take a couple of
seconds to complete, but the home sequence could take a minute
to recover.
- Symptom
- Mechanisms will not move and complain of errors.In
particular the grating appears to be in an unknown state and
will not home.
- Problem
- Sometimes when the motor crate is powered on following
installation or removal from the telescope, the motor crate
comes up in an odd state.
- Solution
-
- showpower on mosfireserver. Motor Box
power should be ON
- modify -s mosfire pwstatb5=0 turns off the
motor power. you can verify with a showpower command
- modify -s mosfire pwstatb5=1 turns on
the power
- Attempt to home or move the mechanism.
- Symptom
- Attempts to move a stage (including
grating, filter, pupil rotator, or hatch/dust cover) fail
immediately with an error similar to this:
MRMS Error (46): Error moving motor. Status is error. Check comms.
Error setting home: ERROR - MRMS Error (46): Error moving motor. Status is error. Check comms.
The STATUS keyword for the stage is
Error instead of OK.
- Problem
- Something is wrong with either the stage, its controller,
or its server.
- Solution
-
- Attempt to initialize the controller for the stage by
setting the corresponding INIT keyword to
1; e.g.,:
modify -s mmgts init=1
or click the appropriate button on the Home widget
available on the MOSFIRE desktop.
- If the state remains Error, then attempt to
reset the controller for the stage by setting the
corresponding RESET keyword to 1;
e.g.,:
modify -s mmgts reset=1
and try homing the stage again.
- If homing fails, then stop and re-start the individual
server for the stage by selecting
MOSFIRE Control Menu > Subcomponents... > Restart servers...
or manually from the command line via:
mosfire stop mmgts
mosfire start mmgts
then re-try homing the stage.
- If the state remains Error, try power
cycling the hardware. Run the showpower command
to ensure that power is on and determine the name of the
corresponding power keyword. In this case,
pwstatB5 is the power keyword for the motor
control box.
modify -s mosfire pwstatB5=0
then wait 10 sec and issue this command:
modify -s mosfire pwstatB5=1
Then re-try homing the stage.
- If the state remains Error, try executing
the disconnect/connect scripts from the background menu by
selecting:
MOSFIRE Engineering Menu > mosfire disconnect
followed by
MOSFIRE Engineering Menu > mosfire connect
- If this fails, then run the disconnect script again via
MOSFIRE Engineering Menu > mosfire disconnect
then have summit staff verify/re-seat all MOSFIRE
connections, then reconnect via:
MOSFIRE Engineering Menu > mosfire connect
- If this fails, then try replacing the controller. An
instrument support tech on the summit will be required
for this task.
- Symptom
- FCS button on the control desktop turns red or off.
- Problem
- FCS has failed or the server has lost communication with FCS.
- Solution
- Proceed in this order until FCS turns on. Be patient after each step, sometimes it takes a few seconds for the GUI to update the FCS status.
- Attempt to turn FCS on via keyword:
modify -s mosfire fcson=1
modify -s mfcs enable=1
- Stop and restart the global server and fcs subserver.
mosfire stop mosfire
mosfire stop mfcs
mosfire start mfcs
mosfire start mosfire
mosfireRecoverMfcs
- Check the FCS engineering GUI and toggle the power and enable buttons.
- Restart servers with power cycle of the FCS
mosfire stop mosfire
mosfire stop mfcs
- Power off the FCS controller. You can use keywords (
modify -s mp2s PWSTAT7=0) or the power control GUI (FCS Controller is in Cabinet B).
- Wait 10 seconds.
- Power on the FCS controller.
mosfire start mfcs
mosfire start mosfire
mosfireRecoverMfcs
- Full Powercycle (the hammer)
mosfireDisconnectWithDate
mosfireConnectWithDate
restart the Augmentix server
- Symptom
- When selecting an intermediate band
filter (J2, J3, H1, H2), the filter wheel in the Mechanism
Status of the MOSFIRE Desktop shows a big red question mark
symbol.
- Problem
- The filter is in position but one of the three switches
associated to its position was not activated. This type of
error might appear for observers using the observing mode
J2-spectroscopy.
- Solution
-
- Ask you support astronomer to log into a terminal as
user moseng.
- In the moseng terminal, type in mmf1s. The
output will look similar to this:
=======================================
Filter Pos Location Switch Binary
=======================================
open 0 0 2 010
J2 1 3472 3 011
J3 2 6944 4 100
H1 3 10416 5 101
H2 4 13888 1 001
NB1061 5 17360 6 110
=======================================
Current
=======================================
unknown 1 -67589 7 111
=======================================
Note the negative value in the Location column at the
bottom of the previous table.
- Force the Switch value for the
unknown Pos to be 7.
modify -s mm1fs switch1=7
This should elliminate the question mark from the filter
in the Mechanism Status GUI.
- Once the J2-Spectroscopy observation has been finished:
If the filter wheel move ends in the unknown position,
repeat the last two steps.
- Symptom
- The Quick Dark or Dark Imaging on
the MOSFIRE Desktop
become unresponsive.
- Problem
- Unknown.
- Solution
- Select dark imaging mode with the following command on a
mosfireserver terminal:
modify -s mosfire setobsmode=Dark-imaging
- Symptom
- The CSU status window indicates that the CSU is not
"ready". The result of executing the command
show -s mosfire csuready
is zero.
- Problem
- The CSU needs to be reset.
- Solution
- From the background menu, select:
MOSFIRE Engineering Menu > Trouble Recovery Menu > Power Cycle CSU
- Symptom
- When attempting to execute a CSU move, the move fails
immediately. CSU status indicates the following error:
Setup failed: Error sending move command
The CSUREADY keyword is set to a value of -1.
- Problem
- The CSU needs to be reset.
- Solution
- From the background menu, select:
MOSFIRE Engineering Menu > Trouble Recovery Menu > Power Cycle CSU
- Symptom
- The bars did not reach the intended location. As an
example, the image below shows several bars in a long slit
configuration that did not fully close to the desired slit
width.

- Problem
- In the
image above, it is suspected that a single tooth was missed
(10 May 2012). Alternatively, a neighboring bar may have
pushed the bar out of position.
- Solution
- Initialize the out of position bars then re-setup and
re-execute your mask. To initialize a subset of CSU bars:
- If the bar is more than what looks like an alignment box away
from the desired location:
- run m csuinitbar=# where # is the desired bar number seen
on ds9.
- repeat for other bars.
- If the bar looks like a box but and is a box length from the
desired location (this is quicker than above, but can cause a fatal
error if the bar is far from the intended destination:
- Pull-down: "MOSFIRE Engineering Menu" -> "Trouble
Recovery Menu" -> "CSU Bar Subset Init" calls mosfireCSUQuickInit
- Answer "y" to continue running the script
- Enter the bars to be initialized, e.g.34 35 36
37, and hit enter
- Once complete, use MAGMA to re-setup and re-execute your mask
If all bars must be initialized (this takes 20-80 min
depending on bar current positions),
then the procedure is:
- Set the CSU to "open" mask from the MAGMA UI.
- Reset all bars using the command
m csuinitbar=0
- Symptom
- While setting up the CSU bars for a new mask, the CSU
status at the top of the CSU status gui indicates an error:
"Status: Setup Failed. Error setting up bar target
positions." MAGMA button never reactivate and you can not
proceed to configuring a mask.
- Problem
- CSU setup failed.
- Solution
-
- modify -s mcsus startCSU=1 In a mosfire server
window
- Re-send the CSU mask setup and execute the mask
If this fails, try stopping and restarting the keyword servers
mcsus and mosfire. Then try power cycling the CSU. This worked
on March 29 but it is unclear what cleared the error.
The mcsus dispatcher has a state variable that tracks whether
the csu_bar_state file is "valid". It is flagged as invalid if
it cannot be read or written. The only way to mark it valid is
to explicitly read or write the state file by setting
READSTATE=1 or WRITESTATE=1 via a command-line modify. The
STARTCSU keyword will not proceed unless it has internally
flagged the csu_bar_state file as valid.
- Symptom
- While configuring the CSU bars for a new mask, the CSU
status at the top of the CSU gui indicates one of the
following errors:
Status= FATAL ERROR
Status= FATAL ERROR and Control Rack Errors: [23:32]
For the two above errors, the CSU faulted while attempting
to move bars.
- Problem
- The CSU electronics have faulted.
- Solution
- First, image the CSU mask. Set H or Ks band imaging and use a 2-6 second
exposure time. Use this image and the bar position overlays in ds9 to evaluate
which of the situations below you are in. Note that the bar position overlays
are approximate and not pixel perfect, but they should tell you if the system
has completly lost track of the bars or if they are only off a little.
- To recover, execute the appropriate recovery option below based on
the state of the system.
- Only a few bars have failed
In this case, we just need to initialize a few bars which has to
be done one at a time.
- Power cycle the CSU until it comes back in a cold state. This
can be done from the background menu
(
MOSFIRE Engineering Menu -> MOSFIRE Troubleshooting Menu -> Power Cycle CSU)
or via the command line using csuPowerCycle. If after power cycling the CSU several times
it does not come up, check that the CSU is connected.
- For each failed bar, initialize it using:
m csuinitbar=N
where N is the bar number (1-92).
- Many or all bars have failed and some of the positions are way off
This is the worst case scenario, Unless you are a MOSFIRE ninja, your best
option is just to do a full init which takes a while (~90 minutes).
If not all bars have failed, you can initialize them one at a time using
the process above for "Only a few bars have failed". Running
m csuinitbar=0 simply initializes each of the 92 bars one
after the other, so if you are paying attention, you can save a little
time by just initializing the bars in an error state one at a time, but
if you are not efficient, it may be faster to have the system iterate over
all 92 bars rather than to have you iterate over a large number of bars
manually.
- Power cycle the CSU until it comes back in a cold state. This
can be done from the background menu
(
MOSFIRE Engineering Menu -> MOSFIRE Troubleshooting Menu -> Power Cycle CSU)
or via the command line using csuPowerCycle. If after power cycling the CSU several times
it does not come up, check that the CSU is connected.
- Perform a full init using:
m csuinitbar=0
This will take a while (~90 minutes), but it the safest and easiest option.
- Many or all bars have failed, but the positions are not far off
If this is the case, you still want to initialize the bars, but it would
be advantageous to have them near the open position so that they start the
initialization process close to the destination. Since we know from the
image that the control system thinks that bars are near their correct
positions, we know that by moving them to the OPEN mask, they won't crash
in to the limits unintentionally. Don't do this if the bars are not within
~20 pixels of their expected position.
To achieve this, we will first trick the CSU in to thinking those bars
are ok (i.e. not in an error state), then we will move them to an OPEN mask,
finally, we will run a full init.
- Log in to mosfireserver as user mosfire:
ssh -X mosfire@mosfireserver
- Edit the file which records the bar states:
emacs -nw /sdata1300/logs/server/mcsus/csu_bar_state
The file is a 3 column, comma separated values file. Change the last
column's value to 0 (OK) for all 92 bars.
- Power cycle the CSU, forcing it to read the
state file:
csuPowerCycleWithReadState
After this completes, the CSU should be ready to move and all bars
should be "OK" in the CSU Status window of the MOSFIRE Desktop.
- In MAGMA, setup, then execute an OPEN mask.
- Initialize all bars using:
m csuinitbar=0
- After recovery is complete, you should be ready to setup and execute
a science mask. It is advisable to image the mask to verify that the
mask looks correct before proceeding with science.
- If CSU fatal erros happen back-to-back or frequently
during one run, suspect CSU electronics are too cold. Adjust
the goycol flow and bring up temperature as in Amplifier Error
- Symptom
- While configuring the CSU bars for a new mask, the CSU
status at the top of the CSU gui indicates one of the
following errors:
Status= FATAL ERROR
Status= FATAL ERROR and Control Rack Errors: [23:32]
For the two above errors, the CSU faulted while attempting
to move bars.
Note that this edge detect process doesn't always work, but can be useful
and save time if it does work.
- Problem
- The CSU electronics have faulted.
- Solution
- Edge detect init is appropriate in situations when
most of the bars were moving when CSU fatal error
occurred, including:
- reconfiguring from one mask to another;
- configuring to open mask;
- configuring to large longslit.
Follow these steps to complete a Kassis Init:
- From the pull down menu select
MOSFIRE Engineering menu > MOSFIRE Trouble Recovery Menu > CSU:ID bar positions.
This will:
- launch an xterm running IDL and start recovery
script;
- configure MOSFIRE for imaging;
- acquire a direct image of the slits;
- display measured bar positions on ds9 image
display utility;
- measure the bar positions; NOTE: if the
positions of some bars cannot be determined, then
you must perform a Full Init as described below.
- launch a second xterm and execute
the CSU power cycle script ;
- prompt user to continue;
- halt the CSU (modify -s mcsus stopCSU=1)
- power off the CSU drives and controller;
- execute showpower to verify that
power is now off;
- pause for 10 sec;
- power on the CSU drives and controller;
- start the CSU (start_csu_cold) and
exit second xterm;
- wait for user to enter Y in first
xterm;
- acquire new image of the mask;
- Assess whether the actual bar positions visible in
ds9 agree with the predicted bar positions slits marked
in green. If not, then abandon the Kassis Init method
and perform a Full Init instead.
- Setup and execute an OPEN mask and wait
for bar moves to complete.
- Perform a full recovery of the CSU bars
via
modify -s mosfire csuinitbar=0
- Wait for the CSU to complete the initialization by
monitoring the CSU status gui completion bar. Note:
do not try to send setup files or move until the
initialization process is completed.
- When finished, setup and execute the desired next mask.
- Symptom
- While moving the CSU, the CSU throws an error. The CSU
status indicates "Aplifier Errors: 40:128" for example. The 40
is the bar number and may be 1-92.
- Problem
- Suspect that the electronics for the CSU are too cold. All
instances of amplifier errors resulted when the amplifier boards
for the bar clutches and brakes were too cold ( between
2-13C ). There may be other reasons for the amplifier error, but
those are not yet known.
- Solution
- So if we suspect that the temperatures are too cold, issue
"cabtemps" on the mosfire server. The temperature to note is the
"Between CSU chassis." If it is below 13 C, you may suspect a
temperature sensitive amp board. Typical output looks like
this:
[61] mosfire@mosfireserver: cabtemps
MOSFIRE Cabinet Temperatures (K)
===========================================================
Sensor Location Temp
-----------------------------------------------------------
exttmp1 Air Return 12.62
exttmp2 Between CSU Chassis 18.20
exttmp3 Middle Right Back of Cabinet 16.33
exttmp4 TBD n/a
exttmp5 Dewar Inner Window 15.67
===========================================================
Log File
-----------------------------------------------------------
/kroot/data/mosfire/logs/housekeeping/160127_mdhs.log
Logging is on
MOSFIRE Glycol Status
===========================================================
Keyword What Status
-----------------------------------------------------------
glysupflow Supply Flow
glyretflow Return Normal
===========================================================
Log File
-----------------------------------------------------------
/kroot/data/mosfire/logs/housekeeping/160127_mdhs.log
Logging is on
So what do we do?
- Ask the OA to send the telescope to horizon and point
it such that you can get to Cass.
- Send MOSFIRE to stationary 0 drive angle
- On the telescope adjust the glycol flow meter from full open
to 0.4 gpm.
- Wait for the temperautre for "Between CSU Chassis" to
rise above 13C.
- Follow standard recovery methods for the CSU. Note that you may
only need to initialize the failed board.
- please be sure to indicate in the nightlog entry
which bar had the amp error so that we can track down
which amplifier board may be at fault.
The two photos below show where and what to adjust. The
glycol flow meter is located on the left hand
side of the instrument when the instrument is at PA=0
stationary mode. The second photo is a view of the flow
meter and brass needle valve. The image shows the setting
for full open with the red line all the way to the
the bottom, which is marked open. Adjust the needle valve until the red line falls to
the 0.4 gpm which is marked on the flow meter display.
Image of back of the electronics cabinet. Flow meter
located on the bottom left. Click to enlarge image.

Image of the flow meter and brass needle valve. Click to
enlarge image.

- Symptom
- testAll and the e-mails sent by crons suggest that the
inner window temperature is out of range.
- Problem
- If the temperature is too low, then the heater power may
not be on. Check this by showing the value of the keyword.
show -s mdhs volt1
If it reads ~0 Volts then the power is not on. If it is ~20
Volts the power is on. There is no in between. 20 or
0. That is it.
If the power is 0, then it is likely that the Kepco
power switch in th electronics cabinet is toggled off, and
you will need to manually reset it.
Check the plots of the Dewar Window Temps
and Window Heater
Voltage which will help you confirm that it was
toggled off.
- Solution
- Turn the Kepco switch to the on position.
- Rotate MOSFIRE if necessary to the on deck park
position. This has the compass rose on the back of the
instrument pointing up and to the right.
- open the right bay door.
- find the panel/tray that says Kepco power
supply. This tray also has the MAGIQ guider electronics.
- Check the position of the "Kepco Crowbar Reset
switch" located on the right hand side.
- toggle the switch to the on position.
- Now run
show -s mdhs volt1
and check
that volt1=20 V.
- run cabtemps and monitor the window temp. You
should see it start to return to the operating range.
- Symptom
- Temperatures appear to be warming, following a unexpected
power cycle of CCRs or observatory-wide power.
- Problem
- CCRs are running but not at their default configurations.
- Solution
- To restart the CCRs with their default power using the
script mosfireResetCcrs.
- Symptom
- Temperatures appear to be warming slowly.
- Problem
- CCRs are running but unable to maintain stable temps.
- Solution
- Increase the speed of the CCRs.
- For example, to set 50 RPM:
modify -s mscs rpmtarg1=50 rpmtarg2=50
- To confirm the change, first run:
modify -s mscs pollhw=1
- Then check the resulting values with:
show -s mscs -terse dacout1r dacout2r
- Symptom
- Mask alignment fails because there are bright edges to the alignment boxes.
- Problem
- The FCS is failing to position itself properly. This seems to be related to temperature as it happens predominantly in cold weather. We think that the FCS loses some if its dynamic range, so it may also happen only on objects where the FCS is at a large fraction of its range (> ~90%).
- Solution
-
Check the individual image and the difference image (in Frame 2) in ds9. If the alignment boxes are moving within a single image or have moved between the target and sky image, then this is the culprit. If the system seems to have stabilized (i.e. boxes are stable between subsequent images), then try to align again by taking a new sky image ("Start Fine Alignment" button).
If the alignment simply can't be done, check the range used by the FCS. If it is large (~90%), try going to a different object, then coming back to this one after a while when the elevation and rotator drive angle will be different and try again.
 |
| An example of a doubled image. The FCS has moved during the exposure causing the characteristic doubled alignment box (and star). |
- Symptom
- Guider is way out of focus with huge star images and instrument is in focus.
- Problem
- The guider galil controller has likely been power cycled and has ended up in a bad state.
- Solution
- Follow the procedure in night log K1-23678 (reproduced below).
- log into k1-magiq-camserver2 as k1obs
- To initialize the focus stage use the following command:
\modify -s msfrmgq mtrtell="cmd[0]=1;XQ#NEWCMDA,1"
- Be patient, the init sequence take some time. Guess is 10 min.
- show the current focus:
\show -s msfrmgq focus
it will probably read 0.0
- set the default focus value:
\modify -s msfrmgq focus=14
The response should be setting focus = 14 (wait)
- show the focus to verify the value of 14:
\show -s msfrmgq focus
- execute the focus move:
\modify -s msfrmgq mtrtell="cmd[0]=2;XQ#NEWCMDA,1"
It will take a few seconds. But the stars should look like stars on the guider.
- Verify the raw focus value:
\show -s msfrmgq focusraw
The result should be focusraw = 1891891. That value is the desired raw counts.
Note: the \ preceding the commands above is required as the show and modify commands are aliased on that machine and we need to invoke the unaliased versions.
{kind=link}